

Spotify Data Tech Stack
Learn how Spotify ingests 1.4T+ events daily on GCP via 38K+ data pipelines, leveraging BigQuery, Dataflow, and Flyte to power ~5K dashboards and scale data-driven insights.

Explore how Spotify processes over 1.4 trillion data points daily to power personalized experiences for hundreds of millions of users worldwide. This overview distills the essential tools, architectures, and innovations Spotify employs for data ingestion, processing, storage, and analytics.
Metrics
1.4+ trillion events processed daily.
670+ million monthly active users.
38,000+ Data Pipelines active in production environment.
Spotify runs the largest Hadoop cluster in Europe.
1800+ different event types representing interactions from Spotify users.
~5k dashboards serving to ~6k users.

Content is based on multiple sources including Spotify Blog, Open Source websites, Job descriptions and other public articles etc. You will find references to dive deep as you read.
Platform
Google Cloud Platform (GCP)
GCP is Spotify’s core cloud provider, supporting both compute and advanced analytics. Spotify migrated from AWS in the mid-2010s to leverage GCP's scalable infrastructure, big data, and machine learning services.
📖 Recommended Reading: Spotify Case Study
Messaging System
PubSub
Spotify moved from Kafka to GCP Pubsub for ingesting their massive amount of event driven data back in 2016.
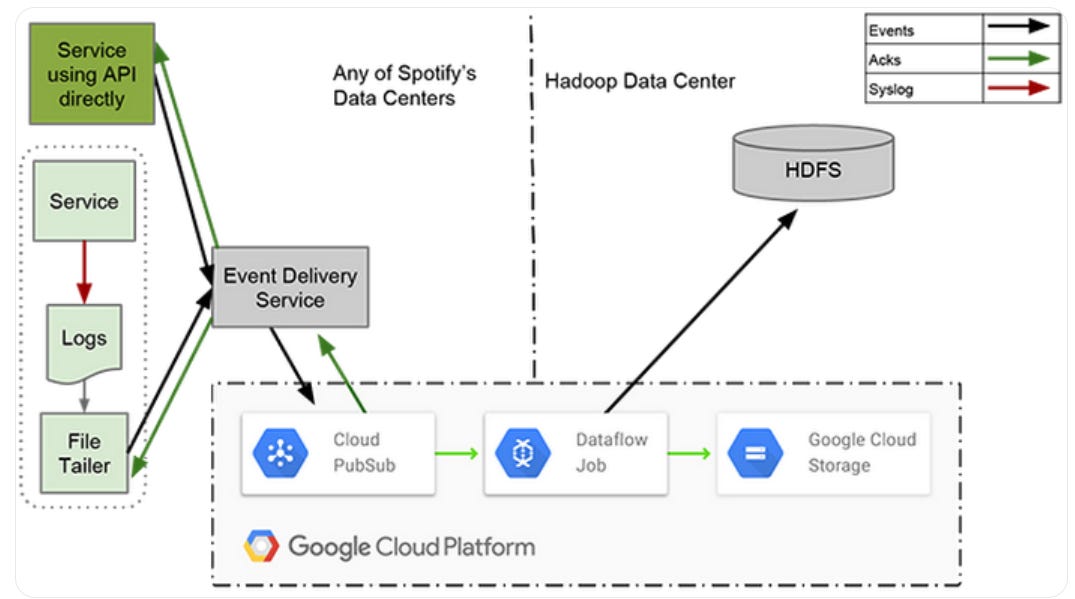
As per recent article, their data platform supports automatic deployment of PubSub, anonymization pipelines and streaming jobs.
Processing
Apache Beam
Apache Beam (GCP Dataflow) is the primary processing tool used at Spotify for handling real time and batch workloads. Spotify has their open source Scala API implementation called Scio.
Scio is a high level Scala API for the Beam Java SDK created by Spotify to run both batch and streaming pipelines at scale. We run Scio mainly on the Google Cloud Dataflow runner, a fully managed service, and process data stored in various systems including most Google Cloud products, HDFS, Cassandra, Elasticsearch, PostgreSQL and more.
— source
Apache Flink
While most pipelines leverage Scio (Beam), Data Platform also supports Apache Flink. There is not enough public information on how exactly they leverage Flink.
Orchestrator
Flyte
Spotify migrated from Luigi and Flo to Flyte starting in 2019 to address challenges like fragmented orchestration logic, limited visibility, and lack of extensibility. Flyte offered a centralized service with a thin SDK, better workflow visibility, caching, and multi-language support.
Today, Spotify uses Flyte to manage and introspect data workflows at scale (38k+ jobs), while execution remains on Kubernetes via their existing Styx scheduler.

📖 Recommended Reading: Why We Switched Our Data Orchestration Service
Warehouse
BigQuery
With their migration to GCP, they also moved to BigQuery as the centralized warehouse, processing SQL based workflows through DBT while storing all the analytical data served through dashboards tools e.g. Looker.
Storage
HDFS / GCS
Spotify maintains the largest Hadoop cluster in Europe, with the on going migration to Cloud, they serve and store data on both on premise HDFS and Google Cloud Storage.
There’s no public information confirming whether Spotify uses a lakehouse architecture.
Management
Spotify has in house tooling for data management as part of their Data Platform, solving the problems from the following common areas.
Metadata
Lineage
Retention
Access Control
📖Read more: Data Management & Data Processing
Dashboard
Looker / Tableau
Spotify provides both Looker and Tableau as the dashboarding platforms. As per 2023, Spotify had 4900+ dashboards serving to 6000+ users across the company.
Tableau is used for complex, highly customized dashboards; so all design flexibility is available for deep-dive internal products with specific user needs.
Looker Studio is preferred for fast, lightweight dashboards; especially among engineering and product teams, thanks to its tight integration with BigQuery and ease of SQL‑to‑visualization workflows.

Related Content:


💬 Spotify’s cloud journey has been unique; starting with on-premise then leveraging AWS and then migrating to GCP in 2016, while still operating some on-prem systems like Hadoop. Today, they rely heavily on GCP-native tools alongside in-house platforms that empower internal teams. I may have missed details, feel free to share in the comments!