

DoorDash Data Tech Stack
Learn about the Data Tech Stack used by DoorDash to process hundreds of Terabytes of data every day.

DoorDash has been a leader in the food delivery service industry, with over 5 billion consumer orders, more than $100 billion in merchant sales, and over $35 billion earned by Dashers. A key factor in their success is their data-driven approach, ingesting massive amounts of event-driven data daily to make informed decisions.
Their Data Platform is powered mainly by open-source tools like Kafka, Flink, and Delta, alongside commercial products like Sigma, which we will explore today.

Content is based on multiple sources including DoorDash Engineering Blog, Careers’ Page and third party articles. You will find references as you read.
Platform
AWS
DoorDash leverage AWS as their cloud platform and utilizes several AWS services. One of the use case has been shared by AWS here.
Storage
S3
S3 is the core component of their Lakehouse, storing Petabytes of data for offline processes, heavily used in Flink and Spark processing.
Delta
DoorDash primarily provide Delta table format on S3 to build a strong Lakehouse architecture. However, according to this job description they also use Iceberg.
Last year, they showcased a Flink + Delta real-time architecture at the Databricks Summit.
Pinot
DoorDash uses Apache Pinot for real-time analytics and low-latency queries. It powers two use cases:
Mx Portal Ads Campaign Reporting by tracking impressions, clicks, and orders.
Risk Platform dashboards built with Superset on top of Pinot Tables.
📹Recommended Video: Supporting Multiple Pinot Use Cases at Scale
Snowflake
Snowflake is the Data Warehouse primarily to support reporting and metrics in Sigma to drive data-driven decision-making. Data is inserted from S3 using Snowpipe.
📖 Recommended Reading: DoorDash Logs a 30% Increase in Queries while Keeping the Snowflake Cost Constant with Sigma
Processing
Kafka
DoorDash uses Apache Kafka as a distributed event streaming platform to handle billions of real-time events. They leverage Kafka for message queuing, real-time event processing, and have implemented multi-tenancy awareness for both producers and consumes.
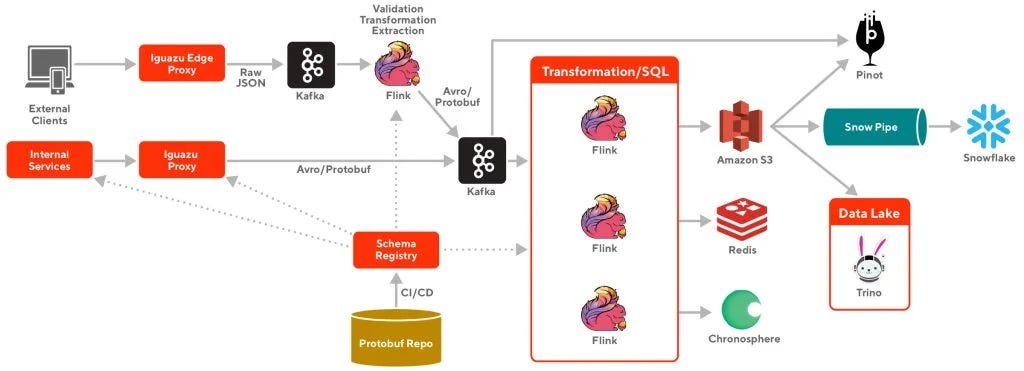
📖 Recommended Reading: Real time event processing with Kafka and Flink
Flink
Flink is used as a primary stream processing engine, processing 220 TB per day into their data lake using the Flink Delta Sink.
Airflow
DoorDash use Airflow as its data platform orchestration tool, allowing users to seamlessly orchestrate complex pipelines with Spark while accessing data from their Lakehouse.
Spark
Spark is the core Batch Processing Engine, enabling users to perform large scale data transformations and aggregations.
Trino
Trino allows DoorDash’s data team to seamlessly query data from the Lakehouse using SQL. It supports both batch jobs and ad-hoc analysis, enabling efficient exploration and processing of large datasets.
📹Recommended Video: How DoorDash is Realizing a Unified Query Engine
Dashboard
Sigma
Sigma is DoorDash's primary Business Intelligence tool, empowering ~12,000 internal users and 5,000 dashboards with real-time data, self-service capabilities, and advanced analytical insights.
Superset
DoorDash use Apache Superset for their Risk Platform, enabling real-time analytics on top of Apache Pinot, according to this source.
Related Content: Tech Stack Series


💬 Let me know in the comments if I missed something.
Great summary, thanks
DoorDash’s data stack is seriously impressive. I like how they mix open-source tools like Kafka, Flink, Spark, and Pinot with AWS to handle massive amounts of data.
Building a Lakehouse on S3 and Delta, plus using Trino, Airflow, and Sigma, shows how carefully they planned for scale and flexibility. Having 12,000 Sigma users is impressive!
Managing real-time and batch like that isn’t easy.
If you were starting from scratch, which tool would you prioritize first?