

Lyft Data Tech Stack
Explore the high-scale data stack Lyft uses to support 25M+ active riders, ingesting millions of real-time events every second.

Lyft operates one of the most data-intensive real-time platforms in the world, processing millions of rider–driver interactions every minute. Behind the scenes is a modern, high-scale data stack built on AWS, Kafka, Flink, Trino, and a 100+ PB warehouse on S3. In this deep dive, we’ll explore how these tools power Lyft’s data, analytics, machine learning, and real-time decision systems.
Metrics
28.7M active riders in Q3 2025, completing ~2.7M rides per day.
Apache Kafka processes millions of real-time events per second for streaming analytics.
Thousands of Airflow + Flyte pipelines orchestrate ETL and ML workflows.
Data warehouse exceeds 100+ PB stored in S3 with Hive Metastore.
Trino ETL executes ~250K queries/day, reading ~10 PB/day and writing ~100 TB/day.

Content is based on multiple sources including Lyft Blog, AWS Blog and other public articles etc. You will find references to dive deep as you read.
Platform
AWS
Lyft’s data and infrastructure are fully hosted on AWS, leveraging managed services and elastic scaling to support real-time transportation and logistics workloads. AWS powers everything from API services to large-scale data analytics, enabling Lyft to handle millions of rider-driver interactions efficiently.
📖Further Reading: Lyft Case Study
Messaging System
Kafka
Lyft adopted Kafka relatively recently to address scaling challenges, as explained in the video below. Kafka facilitates real-time data streaming, processing millions of events per minute, and supports various use cases such as trip updates, driver location tracking, and telemetry ingestion.
Kinesis
Alongside Kafka, Lyft also leverages AWS Kinesis which was introduced at Lyft long before Kafka. There is not enough public information about the plans if Kinesis will be replaced by Kafka.

Processing
Flink & Beam
Lyft adopted Apache Flink as the core real time and streaming engine to support wide variety of use cases. They leverage Apache Beam on top of the Flink runner due to portability and multi language capabilities.
Below is the video from the summit where you can learn more on how these tools are used at Lyft.
Spark
Lyft leverages Spark mostly on the Machine Learning side, e.g. LyftLearn, a ML platform which streamline Spark-on-Kubernetes for improved resource allocation, SQL adaptability, and integration with ML libraries. This seamlessly integrates with the orchestration tool Flyte.
📖 Recommended Reading: Spark At Lyft
Trino
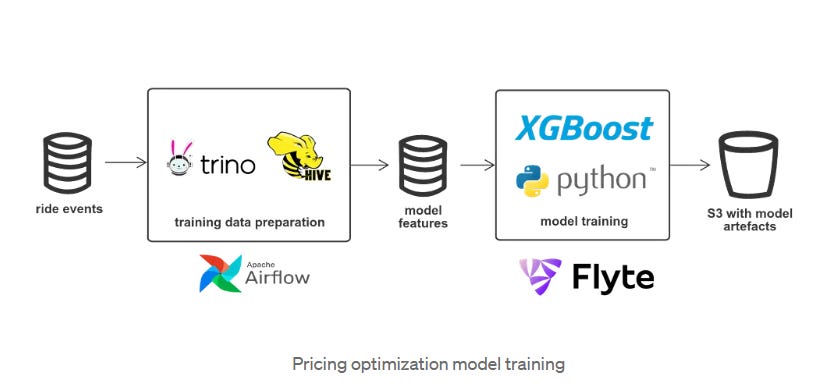
Lyft uses Trino it to power large-scale ETL workloads that read 10 PB and write 100 TB of data daily from its Hive warehouse. Trino also serves as a fast, user-friendly query layer for teams, with over 90% of queries completing in under three minutes.
📖 Recommended Reading: Trino for large scale ETL at Lyft
Orchestrator
Airflow & Flyte
Lyft provides two orchestration platforms Airflow and Flyte, each having its pros and cons. Historically, Airflow has been widely used across Lyft for building data pipelines, while Lyft developed Flyte focusing on high intensive tasks like Machine Learning.
📖 Read more: Comparing Flyte and Airflow at Lyft
Warehouse
S3 & Hive
Lyft’s core data warehouse containing 100s of petabytes runs on top of Amazon S3, with Hive used as the metastore. While Lyft hasn’t publicly stated using modern open table formats like Iceberg or Delta, their S3 + Hive setup still powers large-scale historical storage.
Catalog
Amundsen
Developed in-house and open-sourced, Amundsen is Lyft’s metadata and data discovery platform. It provides a centralized catalog for datasets, dashboards, and pipelines, integrating with Hive Metastore, Trino, and Airflow to surface ownership, lineage, and documentation. Amundsen has since become a leading open metadata framework adopted across the industry.
📖 Learn more: Amundsen: Lyft’s Data Discovery Engine
Data Store
ClickHouse
Lyft faced key challenges like data deduplication using Apache Druid, which prompted their migration to ClickHouse. This switch not only resolved those issues but also delivered improved performance and operational efficiency for real-time analytics.
📖 Recommended Reading: Druid Deprecation and ClickHouse Adoption at Lyft
Dashboard
Superset
For visualization, Lyft primarily uses Apache Superset, which connects to Trino as its query engine, to deliver both analytics and operational dashboards.
As per this article from 2019, Lyft supported multiple dashboarding tools, there is no recent public information whether the tools are consolidated or still supported.
Related Content:


💬 Overall, Lyft blends AWS with cloud-native and open-source systems to support massive real-time data processing, analytics, and machine learning across its platform.