

Benchmarking Spark - Open Source vs EMRs
Diving into four approaches from Spark Operator to EMR (EKS, EC2, and Serverless), sharing benchmarking results and key insights to help you choose the best option.

Recently, I've been exploring different Spark options and benchmarking batch jobs to evaluate their setup complexity, cost-effectiveness, and performance.
I wanted to share my findings to help you decide which option to choose if you're in a similar situation.
The article covers:
Benchmarking a single batch job across Spark Operator, EMR on EC2, EMR on EKS, and EMR Serverless.
Key considerations for selecting the right option and when to use each.

Job
To benchmark these options, I used a heavy-shuffling Spark batch job written in Scala. Since it was run on a proprietary dataset, I can't share specific details.
Inputs
Dataset A
Size: ~270 GB
File Count: 500
Row Count: ~350 MillionDataset B
Size: ~1 TB
File Count: 500
Row Count: ~3 BillionResource
I used same resources across each approach:
Job runs in us-east-1 region.
Using On-Demand because with Spot the cost and performance will vary depending on how often the job lose the spot.
Ignoring the Driver cost to simplify calculation.
Not enabling or considering the autoscaling feature when calculating the cost, it makes easy to compare and calculate cost.
Using 150 executors, with:
50 GB memory
8 cores
Result
Some Important points to keep in mind while looking at results:
Spark Operator uses the 3.2 version with no custom optimization. It is the existing environment we use, so its not apples to apples, but gives enough idea.
AWS says EMR is 4x faster than open source Spark.
Cost is not the actual bill, calculation shared in the next section.
On paper EMR Serverless might look like the most expensive option, but in reality due to better resource consumption, it is actually the fastest.
Benchmarking can give idea in terms of cost and performance, but there are more factors to consider which are shared later.


Based on just benchmarking results for the specific job, EMR Serverless is the right choice in terms of both cost and performance, but it may not be true in all cases.
Cost Calculation
Calculation is done through AWS calculator based on r5.2xlarge (8 cores, 64GB memory). The actual bill may differ.
Spark Operator
r5.2xlarge Instance fee = $0.504
EKS cost per hour = $0.1
Cost Per Hour:
(Instance fee) * (Number of pods * hours) + (EKS cost * hours)
$0.504 * (150 * 1) + (0.1 * 1) = $75.70
Cost Per Minute:
cost_per_hour * (mins / 60)
$75.70 * (22 / 60) = $27.75EMR on EKS
r5.2xlarge Instance fee = $0.504
EMR fee per hour = $0.15208 (based on 8 cores and 64GB memory)
EKS cost per hour = $0.1
Cost Per Hour:
(Instance fee + emr fee) * (Number of instances * hours) + (EKS cost * hours)
($0.504 + $0.15208) * (150 * 1) + (0.1 * 1) = $98.51
Cost Per Minute:
cost_per_hour * (mins / 60)
$98.51 * (18 / 60) = $31.19EMR on EC2
r5.2xlarge Instance fee = $0.504
EMR fee per hour = $0.126
Cost Per Hour:
(Instance + emr fee) * (Number of instances * hours)
($0.504 + $0.126) * (150 * 1) = $94.5
Cost Per Minute:
cost_per_hour * (mins / 60)
$94.5 * (17 / 60) = $26.7EMR Serverless
EMR fee per hour = $0.7908
Cost Per Hour:
(emr fee) * (resources * hours)
$0.7908 * (150 * 1) = $118.62
Cost Per Minute:
cost_per_hour * (mins / 60)
$118.62 * (11 / 60) = $21.75Which one to Pick?
The biggest challenge as a Team is to pick the right compute infra for your use case. Benchmarking can help, but there are lot of other factors that needs to considered, e.g. complexity, operational overhead, workflow requirements, team dynamics, etc.
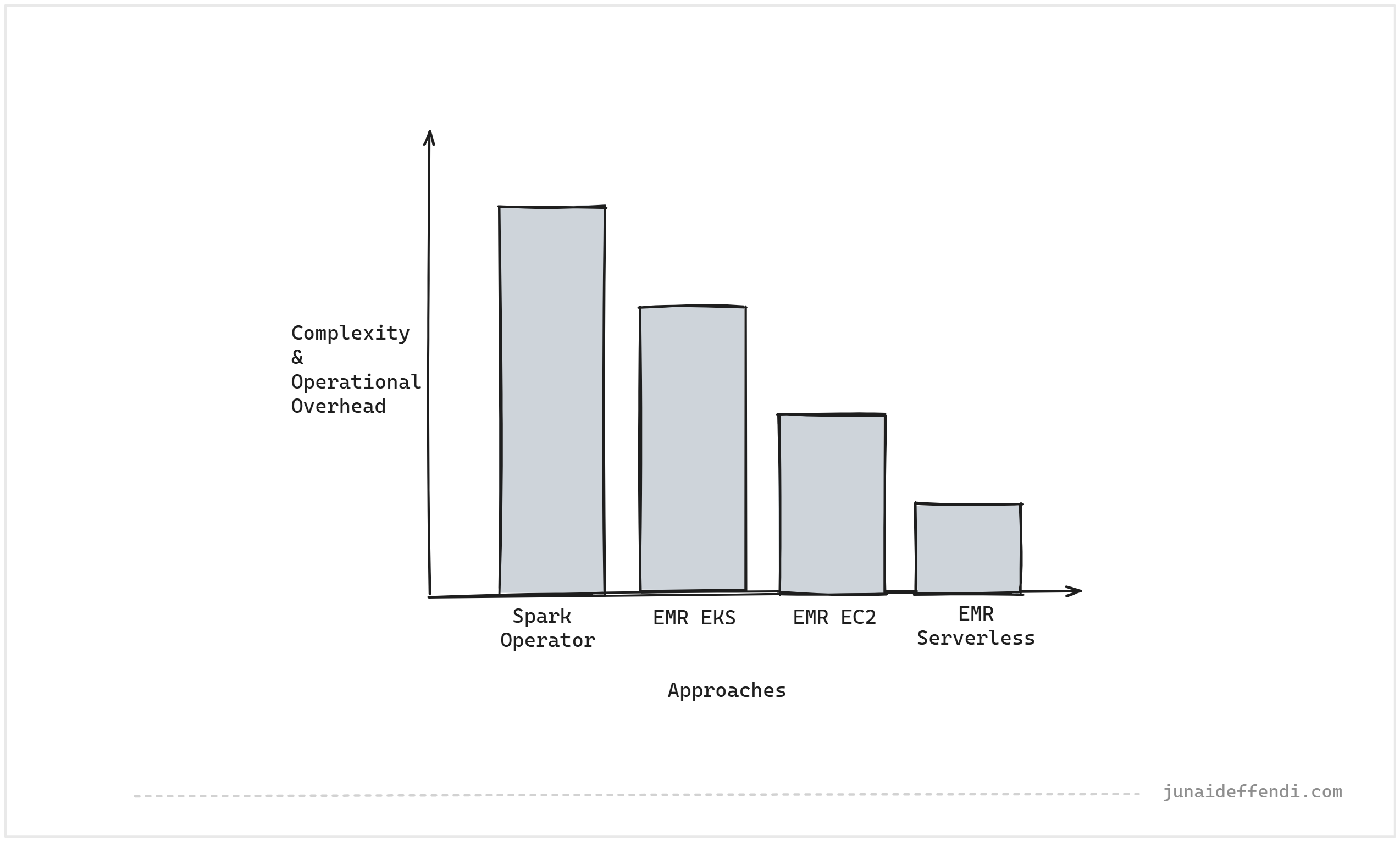
The following key points will help you decide which one to pick and will save time by narrowing down the benchmarking options.
Spark Operator
Complex setup requiring heavy investment upfront with high operational overhead.
Great for dedicated teams which has the expertise of running open source tool and Kubernetes.
Fully customizable, however requires additional setup from Spark UI to performance optimization, e.g. setting up a magic committer for write performance.
For large scale, this will be the cheapest option in the long run if implemented correctly.
Can support both Spot and On Demand EC2 Instances.
EMR on EKS
Bit easier than Spark Operator but still a complex setup requiring similar investment upfront but only on the Kubernetes part.
Spark is fully managed and optimized through EMR giving additional features:
EMR virtual containers console: providing restricted view only mode for Spark jobs with monitoring, logging and Spark UI.
Depending on job type, EMR could be expensive due to additional EMR Service Fee. EMR fee is per resource (memory & cores).
Can support both Spot and On Demand EC2 Instances.
EMR on EC2
Easier than the previous one as no Kubernetes is required, runs directly on EC2. However, requires the expertise of EC2 instances, types, pricing, etc.
Spark is fully managed and optimized through EMR giving additional features:
EMR console: providing boarder control of resources, applications, monitoring and logging, Spark UI.
Depending on job type, EMR could be expensive due to additional EMR Service Fee. EMR Fee is per instance type.
Can support both Spot and On Demand EC2 Instances.
EMR Serverless
Easiest in the list, with no complex infra setup required, no EC2 or EKS.
Go with serverless if small team with small amount of data processing.
Spark is fully managed and optimized through EMR giving additional features:
EMR Studio console: providing control of applications, monitoring and logging, Spark UI.
It is a pay per use model. Depending on job type this could be the most expensive option. EMR Fee is per resource (memory & cores).
Serverless seems to better suited for small size jobs with strict SLAs, which we saw earlier in the benchmarking results.
Only supports On Demand option at the moment.
To simplify in the image form, the following can be used at a high level to narrow down the option to get the most cost effective results.

After narrowing down the options, you can perform similar benchmarking on multiple jobs to get an idea.
💬 Let me know what else would you add.
What would you say about spark on AWS Glue?
Will it be better than EMR serverless for small scale small team?