

Inside Data Engineering with Yuki Kakegawa
A solo data engineer at a SaaS company, Yuki breaks down his stack, his journey, and why the job description matters more than the title.


In this edition of Inside Data Engineering, Yuki from The Data Toolbox breaks down what the role really looks like when you’re flying solo, where GenAI actually helps (and where it doesn’t), and why the job title matters less than the job description.
What to Expect:
The Solo DE Experience – What it means to own the entire data function at a company, end to end.
Breaking In – How Yuki went from CS student to the only data person in the room.
Tech Stack in Practice – A real-world look at Airbyte, BigQuery, and SQLMesh working together.
GenAI Honestly – Where it helps, where it doesn’t, and the balance that’s hard to get right.
Hot Takes – Why the semantic layer hype might be getting ahead of reality.
⭐ If you're curious about data engineering or considering it as a career, this series is for you!

Let’s dive into Inside Data Engineering:
How did you get into Data Engineering, and what does your role look like today?
I’ve always been interested in the idea of putting your business idea into an app or software, which led me to study computer science in college. And that’s when I learned about those fancy terms like data science and machine learning and I started studying them on my own. That eventually led me to the realization that the foundational data work matters more to the businesses in general. I initially started more on the front end side of things like basic analytics and visualization work, but over time my work and interest shifted towards building data pipelines and analytical models, though I still do and like front-end work.
I’m currently the only data person at my company. That means I’m doing everything from talking directly to the business and building data solutions for them. I even help create high level things like the company data strategy and roadmaps.
In simple terms, how would you explain what a Data Engineer does to someone new?
A data engineer builds systems that reliably and scalably move data from point A to point B at an expected cadence. A data engineer also may transform and manipulate data so that people using it will have an easier time understanding, analyzing, and utilizing it.
What does your typical day or week look like?
You’d typically have a few meetings in a day. It may be a daily call with the internal engineering team, or it may be a meeting with folks from the business side, coordinating with and unblocking each other on a project. I usually have a solid few hours at least to do the hands-on part of my projects. I may be adding a new data ingestion script or connector for a new source system, building analytical data models, or developing dashboards or analyses for the business to consume data.
What kind of problems do you solve with data, and why do they matter to the business?
What I do has to do with the logic the business needs to do their reporting and analytics. Without any business logic, data isn’t useful.
What kind of data and scale do you work with, and who typically uses the data you build?
My company is a SaaS business. So, app users, customers data, as well as revenues we generate from our customers, as well as app usage data.
Literally every department uses the data. Revenue reporting for finance, app usage for Product and CS, users and customers data for CX, CS, and Product
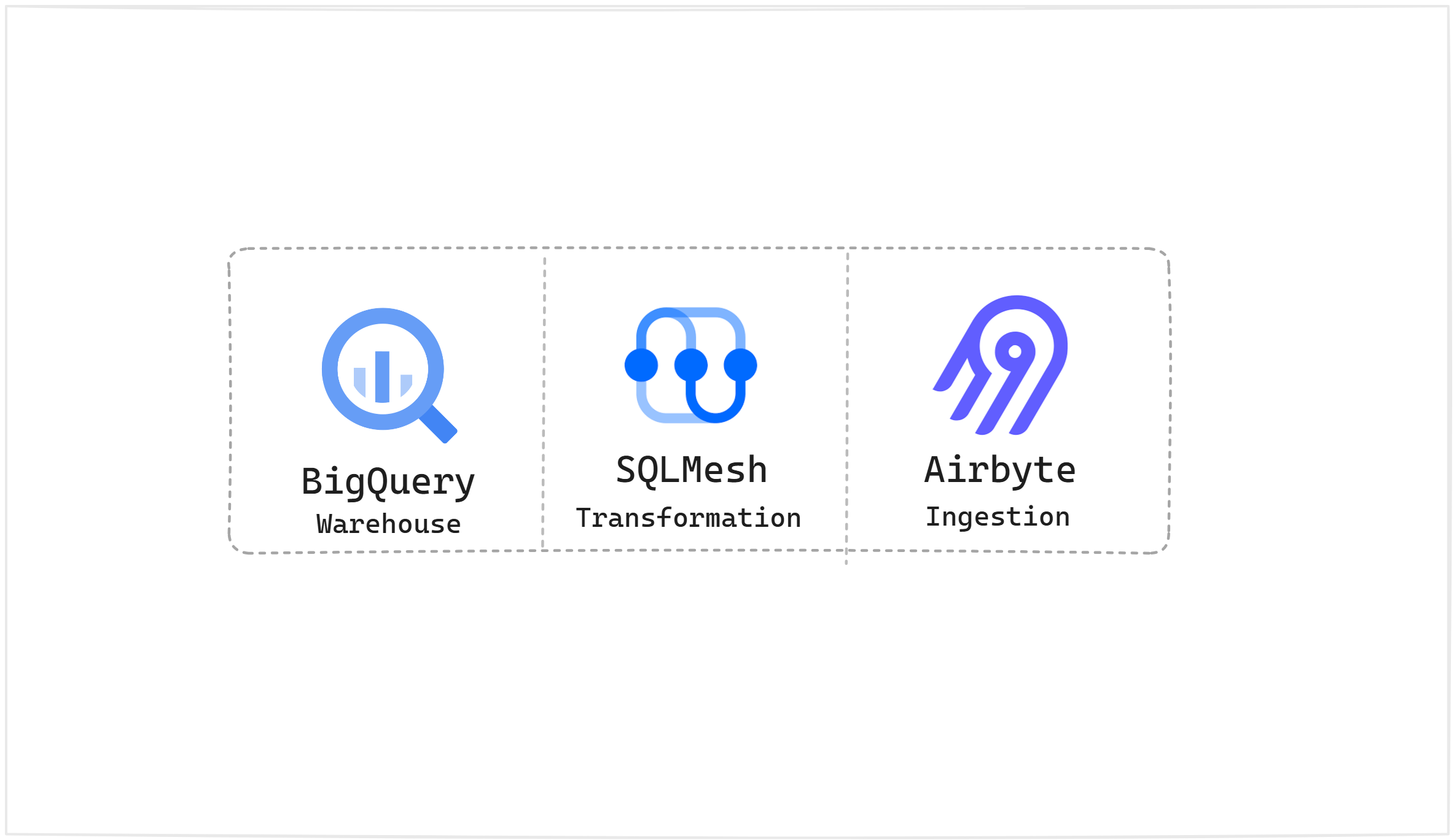
At a high level, what does your data platform look like (from ingestion to consumption), and why was it designed that way?
We use Airbyte for ingestion, BigQuery for the data warehouse, SQLMesh for the data transformation framework. The company had some tools in place already before I came up such as Airbyte and BigQuery, and I added a few things to make them more efficient and scalable, without changing the overall architecture and design.
What’s something challenging or unexpected about Data Engineering that people don’t usually realize?
The role varies depending on the company you work at. “Data Engineering“ can mean building data infrastructure and its management including DevOps like work, or it can mean just building analytical models in the cloud data warehouse. The job description matters more than the title.
Where do you see GenAI helping (or not helping) Data Engineering today?
It’s helping where the problem is purely technical. But once you’re working on something that involves many human elements, like defining and aligning on data or metrics definitions, AI can help, but only to a limited extent.
It’s not easy to strike the best balance of being efficient with AI. Who knows if you would’ve come to the same or better conclusion or solution with or without AI?
What advice would you give to someone considering a career in Data Engineering?
Start and continue networking and expand your connections. Stay curious and have the attitude for learning.
What do you think is overhyped vs genuinely important in the future of Data Engineering?
The importance of having a dedicated semantic layer is a bit overhyped IMO. It’s crucial, especially if your metrics support many use cases (not just internal reporting). But you can also go far with clear documentations and metrics definitions in a glossary and some kind of enforcement in place. All that to say, just because semantic layer seems important, nobody should just jump on to buying and implementing a full-featured semantic layer tool.
I hope this article was helpful for the readers. Thanks to Yuki for sharing his experience with my audience. Stay tuned for more!
Please reach out if you like:
To be the guest and share your experiences & journey.
To provide feedback and suggestions on how we can improve the quality of questions.
To suggest guests for the future articles.
 | A guest post by
|
Data engineering feels less about the title and more about owning the whole data flow and making it actually useful for the business